
Richtige Datennutzung für höhere Prozessqualität und Wirtschaftlichkeit
Speichern Sie noch oder wissen Sie schon
-
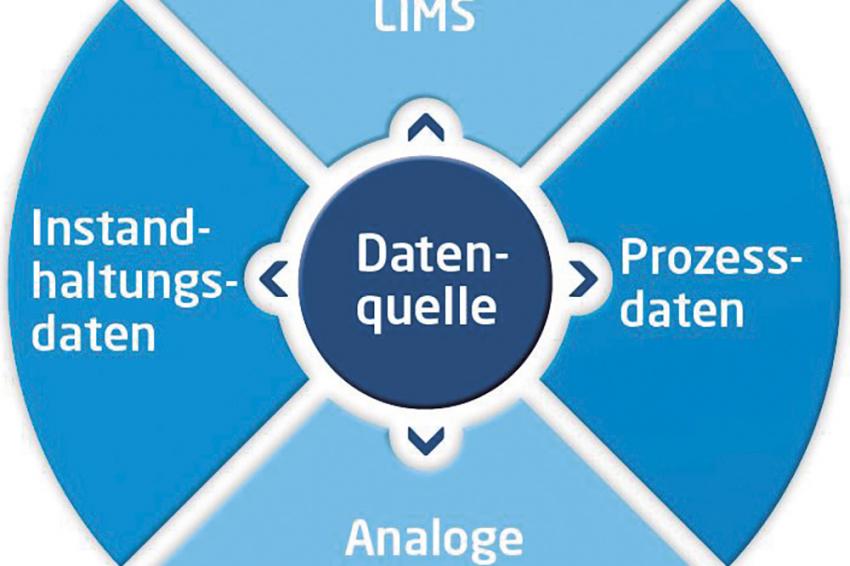 Produktions-, Prozess- und Anlagendaten werden heute meist dezentral in verschiedenen Speichermedien abgelegt und verwaltet. Die unterschiedlichen Datentypen leben in klar voneinander abgetrennten Systemen und es gibt selten Relationen zwischen den Datenspeichern © Process Automation Solutions
Produktions-, Prozess- und Anlagendaten werden heute meist dezentral in verschiedenen Speichermedien abgelegt und verwaltet. Die unterschiedlichen Datentypen leben in klar voneinander abgetrennten Systemen und es gibt selten Relationen zwischen den Datenspeichern © Process Automation Solutions -
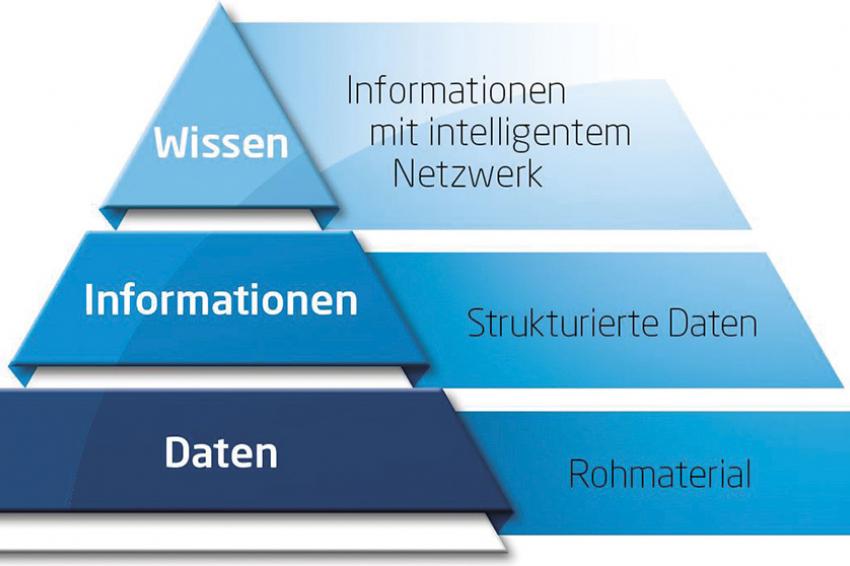 Aus Daten wird Wissen. Mit passgenauen Lösungen für eine effektive Datennutzung, lassen sich Prozess- sowie Produktqualität verbessern und die Wirtschaftlichkeit erhöhen. © Process Automation Solutions
Aus Daten wird Wissen. Mit passgenauen Lösungen für eine effektive Datennutzung, lassen sich Prozess- sowie Produktqualität verbessern und die Wirtschaftlichkeit erhöhen. © Process Automation Solutions
Meist sind die Daten dabei aber so abgelegt, dass nur wenige darauf zugreifen und sie richtig interpretieren können. Das begrenzt den Nutzen der Datenspeicherung enorm. Denn nur wenn die Daten im richtigen Kontext stehen, werden sie zu aussagekräftigen Informationen, die sich verwenden lassen, um Prozess- sowie Produktqualität zu verbessern und die Wirtschaftlichkeit zu erhöhen.
Produktions-, Prozess- und Anlagendaten werden heute meist dezentral auf verschiedenen Speichermedien abgelegt und verwaltet. Die unterschiedlichen Datentypen leben in klar voneinander abgetrennten Systemen und es gibt selten Relationen zwischen den Datenspeichern. Zudem verlieren viele der Daten bereits beim Speichern ihren Kontext, wenn ein übergeordneter Zusammenhang fehlt, was eine effektive Nutzung der gesammelten und gespeicherten Daten verhindert. Erst wenn dieser Kontext bekannt ist, ergeben sich aber aus den Daten verwertbare Informationen. Der Interpretationsspielraum reduziert sich und das Verständnis ist auch ohne langjährige Erfahrung möglich: Bei einem bestimmten Produktionsprozess bspw. sind Temperaturwerte vielleicht nur dann aussagekräftig, wenn gleichzeitig bekannt ist, wie hoch der Druck im entsprechenden Anlagenteil war oder welches Produkt gerade gefertigt wurde. Die Antwort auf die Frage, warum ein Produkt nicht die geforderten Qualitätsansprüche erfüllt, kann also in verschiedenen dezentralen Datenspeichern zu finden sein, die in den richtigen Kontext gebracht werden müssen, und alle Verantwortlichen müssen darauf zugreifen können.
Erst Daten und Kontext ergeben Information
Ein weiteres Beispiel verdeutlicht den Sachverhalt: Bei einem nicht zufriedenstellenden Produkt zeigt die Analytik die Qualitätsabweichung. Über den Zeitpunkt der Probenentnahme werden dann die relevanten Prozessdaten identifiziert und miteinander in Verbindung gebracht mit dem Ergebnis, dass die Temperatur zu hoch war. Nimmt man dann noch die hinterlegten Instandhaltungsdaten zur Beurteilung hinzu, zeigt sich, dass wenige Stunden vor der Probenentnahme ein Regelkreis am betreffenden Anlagenteil repariert wurde. Die Qualitätsabweichung lässt sich also mit der Reparatur des Regelkreises in Verbindung bringen. Der Fehler ist aufgespürt und kann behoben werden. Nur wenn durch den Kontext der Daten „echte“ Informationen zur Verfügung stehen, ist ein solches Vorgehen möglich.
Informationen haben also einen Mehrwert gegenüber reinen Daten. Sie können als Basis für Entscheidungen dienen, z. B. ob auf bestimmte Situationen besonders geachtet oder steuernd in die aktuelle Produktion eingegriffen werden muss. Gleichzeitig sorgen sie für mehr Effizienz. Auslastungslücken werden aufgespürt und der Material- und Energieeinsatz lässt sich bewerten sowie gegebenenfalls optimieren. Die Abläufe werden auch transparenter. Fragen nach dem Verlauf der Produktion der letzten Charge oder wie in einer ähnlichen Situation reagiert wurde, sind meist direkt verfügbar.
Konzepte der Datenkonzentration
Allerdings gibt es keine Generallösung für eine solche Datenkonzentration. Da die Anforderungen der Applikationen differieren, bieten sich unterschiedliche Konzepte an. Die Automatisierungsspezialisten von Process Automation Solutions (PA) bspw. unterscheiden prinzipiell zwischen drei Ansätzen: So sind bei einem „Ad hoc“-Zugriff auf alle ursprünglichen Datenspeicher sämtliche in den Quellen vorhandenen Daten jederzeit verfügbar und lassen sich flexibel auswerten. Allerdings sind dazu genaue Kenntnisse der Datenstrukturen des Quellsystems erforderlich und längere Abfragelaufzeiten müssen in Kauf genommen werden. Kurz gesagt: mit einem solchen Konzept sind detaillierte Auswertungen möglich, es dauert aber immer eine bestimmte Zeit.
Schnelleren Überblick verschaffen sich Anwender, wenn Kennzahlen vorberechnet und über eine Dashboarding-Plattform zur Verfügung gestellt werden. Der Nachteil einer solchen Lösung: Verfügbar sind eben nur die vorberechneten Kennzahlen. Oft bietet es sich deshalb an, auf ein Hybrid-Konzept zu setzen, das vorberechnete Daten nutzt, gleichzeitig aber auch „Ad hoc“-Zugriffe ermöglicht. Flexibilität bei der Auswertung sowie ein schneller und zentraler Zugriff auf gängige Daten lassen sich so miteinander kombinieren.
Wohin geht der Weg?
In den letzten Jahren durchliefen diese Konzepte eine Evolution. Zunächst lag die Datenhoheit ausschließlich in der Verantwortung der Systeme, in denen sie entstanden sind, und Zugriffe wurden nur sehr kleinteilig gewährt. Im nächsten Schritt entstanden Kennzahlen wie OEE (Overall Equipment Effectiveness) oder Einsatzstoffverhältnisse. In der nächsten Stufe werden alle Daten eines relevanten Analysezeitraums in einen temporären Speicher übertragen. Auf dieser Basis ist eine zentrale Auswertung möglich. Der verfügbare Auswertezeitraum ist dabei jedoch begrenzt und das Zwischenspeichern der Daten generiert eine hohe Last in den Quellsystemen.
Vor diesem Hintergrund gilt heute Dashboarding in der Cloud als passende Lösung für zukunftssichere Anwendungen. Bewährte Authentifizierungs- und Autorisierungstechnologien gewähren hier eine hohe Datensicherheit. Zyklische Datenübertragung mit Streaming-Technologie hält die Last niedrig und Daten aus allen Unternehmensbereichen lassen sich mit harmonisierten Strukturen in großen Datenspeichern, sogenannten Data Lakes, speichern. Die Zusammenhänge sind im Datenmodell beschrieben. Die Lösungen lassen sich bei Bedarf vollständig in die Officewelt oder im Browser integrieren. Kombinierte Datenabrufe z. B. aus Qualitäts- und Prozessdaten sind on-the-fly möglich. Die Kosten werden je nach Nutzen abgerechnet; Investitionen für eine eigene Infrastruktur sind nicht mehr nötig.
Was passt für die jeweilige Anwendung?
Soweit die Theorie. In der Praxis ist die Frage, wie sich der Weg in die effektive Datenkonzentration der Zukunft ganz konkret für die eigene Anwendung umsetzen lässt keineswegs einfach oder allgemeingültig zu beantworten. Während die meisten heute bereits viel Vertrauen in die Datensicherheit der Cloudsysteme haben, z. B. wenn es um Prozessdaten (Confidential Information) geht, gilt das für Strictly Confidential Information wie Unternehmenskennzahlen, Rezepturen oder ähnliches nicht unbedingt. Hier lassen sich aber ebenfalls adäquate Lösungen finden, indem man bspw. vor Ort installierte Hardware und cloudbasierte Lösungen kombiniert. Am effektivsten und schnellsten lassen sich solche individuellen Anforderungen dann mit kompetenter Unterstützung bewältigen, wie sie etwa Process Automation Solutions bieten kann. Die Spezialisten verstehen die Anwenderprozesse, analysieren die vorhandenen Strukturen und beraten herstellerunabhängig. In enger Zusammenarbeit mit den Anwendern entstehen so passgenaue Lösungen für eine effektive Datennutzung, um Prozess- sowie Produktqualität zu verbessern und die Wirtschaftlichkeit zu erhöhen.
Die Autoren
Christian Schulte, Process Automation Solutions
M.A. Christine Reiff, Redaktionsbüro Stutensee
-
 Christian Schulte, Process Automation Solutions
Christian Schulte, Process Automation Solutions -
 M.A. Christine Reiff, Redaktionsbüro Stutensee
M.A. Christine Reiff, Redaktionsbüro Stutensee
Downloads
Kontakt
Process Automation Solutions GmbH
Am Herrschaftsweiher 25
67071 Ludwigshafen
Deutschland
+49 6237 932 0









