
Providing Solutions by Making the Most of Biomedical Data
14.09.2023 - Many life science companies generate large swathes of data.
-
 Liesbeth Ceelen, CEO, BioLizard | © BioLizard
Liesbeth Ceelen, CEO, BioLizard | © BioLizard
Perhaps the greatest example of data in biotech is DNA sequencing, but as more companies generate more data, questions — and challenges — arise. How can we deal with increased amounts of data? What can we learn from more data? And how can tools like AI help?
According to an IDC white paper published in 2017, by 2025 there will be 163 zettabytes of data. We’ve become used to megabytes, but now we tend to talk in gigabytes. A phone, for example, may have 512 GB of memory. To put it into perspective, a zettabyte is a trillion gigabytes.
Fortunately, as more data are generated, methods of storing and analysing data have evolved, too. Hardly a day goes by without a news headline related to artificial intelligence (AI). However, for many biotech companies, AI and big data means big questions.
With more and more companies entering the field, knowing where to turn can also be an issue. One company standing out from the crowd is BioLizard, which is headquartered in Ghent, Belgium. It’s perhaps an unusual name, but there’s a reason. Lizards are agile creatures that can adapt to new environments. And when it comes to partnering with biotech companies to help them navigate data, being agile and adaptable are very useful traits. Indeed, companies differ in what they need, so tailoring solutions based on those requirements isn’t just handy, it’s essential. This agility is why BioLizard’s experts call themselves Lizards.
BioLizard, which has clients in Europe and America, offers services and has experience in bespoke software development, data governance and architecture, and bioinformatics and advanced data analytics including single-cell and multi-omics analytics. The company supports biotech, pharmaceutical and diagnostic companies, and research institutions of all sizes to enable data-driven discovery and preclinical, translational and clinical R&D processes.
Liesbeth Ceelen, CEO of BioLizard, and her colleagues acknowledge how big data, AI and the underlying IT infrastructure can pose major challenges to life sciences companies. While they are well aware that smart integration of AI and maximized use of data are key to staying competitive in the drug and biomarker market, many struggle to acquire the necessary expertise to stay on top of developments in data science.
So, how does BioLizard approach making sense of data, and bringing it all into focus?
Liesbeth Ceelen: Biological data are diverse and come from a huge variety of sources. Often, companies find their data are all over the place, and that interpretation is difficult. It can be a real challenge to realise the full potential of data. When you work with BioLizard, we go beyond just tweaking an existing approach. We first figure out what’s really needed, and then create a plan of action. We are not just a technology provider but more of a partner in innovation, offering personalized solutions and support to accelerate your scientific discovery. Data analysis can be daunting, but we break it down into steps, and we have several teams to help along the way.
Could you give us some examples of how your teams work on a project?
L. Ceelen: First, we understand your challenges and translate your research problem into an IT problem to be solved. Adhering to your system’s requirements, we set up a hard- and software blueprint to produce the required output, cost-efficiently and quickly. We break down the project into smaller tasks, and we have expert teams that take care of these. When these individual solutions are put together, these form a complete answer to the client’s request.
We work on a wide range of projects, and that involves everything from setting up new systems to interpret and manage data efficiently, such as developing a software application to interpret complex biological data or designing of a new system for in silico operations. We also consult on implementing best practices for coding and advise on cloud infrastructure. An example of this would be creating web platforms that manage the processing of wet lab samples. In summary, we aim to make your data easier to manage, share, analyze, and report on.
Could you go into a little more detail on your teams?
L. Ceelen: Sure. Data management has recently gained increased importance in life sciences. Today, researchers generate 10,000 times more data per experiment than they did a decade ago, but spend 30% to 40% of their time searching for, aggregating, and cleaning data.
Our data and infrastructure management team ensures that all organizational data are findable, accessible, interoperable, and reusable —FAIR. Effective data management is also essential for generating the best and most accurate scientific insights, because it enables a less biased approach for data collection and analysis, and it means that no data will be left behind or forgotten. Reliable data management and data governance structures are necessary to apply advanced analytics tools like AI or ML.
The AI and analytics team works on projects ranging from single cell data analytics and multi-omics, all the way to protein engineering and design.
The core activities of our bioinformatics team are focused on the processing and analysis of sequencing-related data and its visualization. This includes all kinds of omics-related data, from proteomics to whole-genome sequencing. The range of projects includes things such as examining differential protein expression and post-translational modifications; cell type deconvolution; transcriptomics, proteomics, and whole genome sequencing for biomarker and drug discovery.
And then there’s the software and IT architecture team. They apply modern software and IT tools to biological projects, in order to improve their efficiency and scalability. Like our other teams, they also function as ‘translators’ between different stakeholders in life science companies, bridging the gap between IT professionals, biologists and data scientists.
Of course, there is extensive collaboration between the teams to, for example, perform a differential expression analysis on an RNA-sequencing data set, where the client would also like to build a predictive model on the same data and perhaps an interactive dashboard to further explore the data and results.
Could you tell us about your platform?
L. Ceelen: BioLizard’s proprietary platform is an extension of our software development solutions. We have designed this platform to empower clients to turn data into clear, interpretable, and actionable insights. The platform ensures data stay safe and secure in a closed cloud environment, and we provide user-friendly front-end interfaces with easy export of results and reports.
What can BioLizard help with?
L. Ceelen: BioLizard can support you at every step from disease modelling through to drug development. At the strategic phase of your projects, we use our life science and data science expertise to determine the most efficient and effective course of action to leverage your data and achieve your goals. A solid strategic plan ensures efficient use of resources, realistic expectations, and optimal value generation. We tailor our strategies to align with your specific goals and requirements and make the process of complex data analysis more manageable and outcome-oriented.
We enable consistent and scientifically rigorous interpretation of biomedical data by employing a combination of advanced tools and methods (for example bioinformatics, AI and ML) and user-friendly, interactive interfaces that allow you to deeply engage with your data, to support you in discovery and validation of drugs or biomarkers, extracting insights from existing datasets, and replicating or validating previous publications.
-
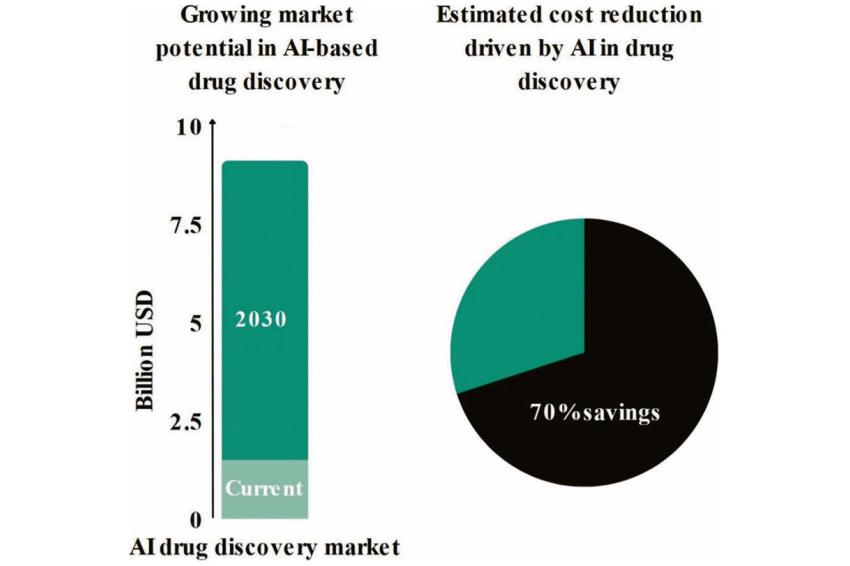 AI is revolutionizing methods for drug discovery and enables massive cost savings by moving research from in vitro to in silico.[1] | © BioLizard
AI is revolutionizing methods for drug discovery and enables massive cost savings by moving research from in vitro to in silico.[1] | © BioLizard -
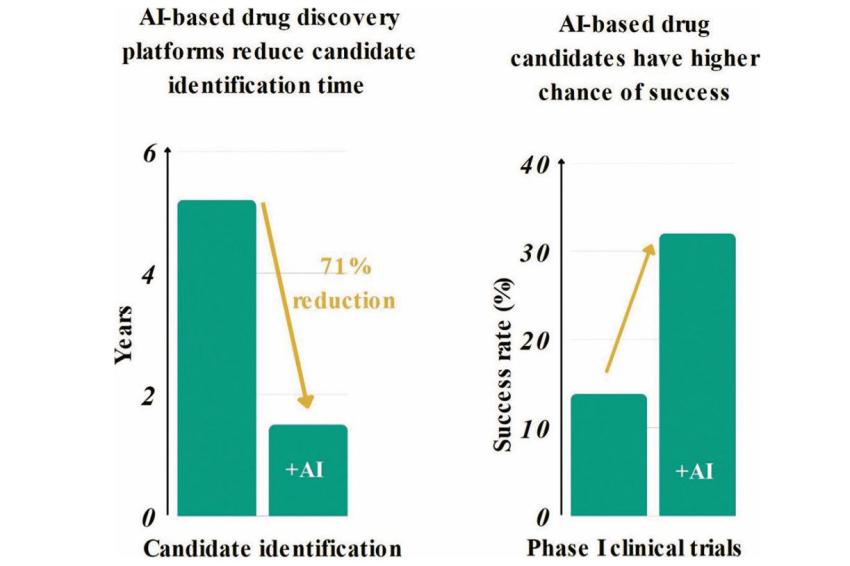 Improved chances for success and time savings by AI-based drug discovery.[2] | © BioLizard
Improved chances for success and time savings by AI-based drug discovery.[2] | © BioLizard
Could you give us an example of this?
L. Ceelen: Yes, on behalf of a client, we have created a software tool for microbiome analysis for modelling causal relationships between microbial community composition or dynamics and their outcomes. This lets us identify modifiable risk factors for the purpose of drug development or find novel biomarkers for microbiome-associated diseases.
For drug discovery & development, we are able to optimize the selection of promising drug candidates to save time in the wet lab. By implementing high throughput in silico workflows to screen potential therapies, we enhance the efficiency, quality, and probability of success of drug discovery pipelines — helping to de-risk and speed up the therapeutics development process. For instance, for our client Madam Therapeutics we mined public data for antimicrobial peptide sequences and predicted activity and toxicity to determine suitable drug candidates.
We can also build in silico libraries for specific use cases. For example, for another client, we set up a drug candidate library and prepared a tailored graphical software to enable researchers to predict whether candidate compounds could be purified via a protein A column. We also supported Calypso biotech with screening for drug repurposing potential by mining data to screen for target compound activity in various disease contexts, to determine new indications for the clients’ proprietary antibody.
What about clinical trials, how can you help there?
L. Ceelen: Well, by combining data on disease pathology and the drug mechanism of action —MoA—, data science can be applied to gain insights into side effects and statistically-effective subject identification and stratification for clinical trials. BioLizard can support you in achieving enhanced understanding of MoAs by integrating multiple layers of data, consolidating in-house data together with publicly available data, and analysing and interpreting complex datasets. Following this approach, we supported a client with AI-based biomarker development to predict clinical outcomes for kidney transplant patients by determining risks for transplant rejection.
As AI seemingly takes over the news headlines, there are many companies emerging to take advantage. So, what sets BioLizard apart?
L. Ceelen: Well, I have to say, we are avantgarde service providers who stay engaged with frontline scientific developments in biology and data science. We bring together almost 50 experts from different scientific fields such as bioengineering, mathematics, computer science and biology. This combined knowledge allows us to truly understand biomedical data challenges as well as software/IT requirements our clients face, and to provide tailor-made solutions suited to their needs. We work in a highly complementary and collaborative manner, meaning that you don’t have to look beyond BioLizard to address all of your data needs.
We are trusted by key players in the pharma and biotech industry, and also have robust experience working in the animal health field as well as in supporting food and agriculture R&D. Next to this, we have established partnerships with producers of cutting-edge technologies like Illumina Connected Analytics Implementation, Parean Biotechnologies, and Tercen that recognize and support us as a skilled and competent biomedical data services partner. Ultimately, it’s all about helping clients achieve biologically and clinically relevant, actionable insights that advance their research in a data-driven way.
We also always comply with security and privacy guidelines, and fully explain our data science approach to solving your biological challenges — there’s no black box when you work with BioLizard. Our ability to ‘speak the language’ of both biology and data science means that we can perfectly fit the needs of our clients every step of the way.
Literature
[1] bit.ly/3ORpDBF; bit.ly/47HVFbV
[2] bit.ly/3YPyWGJ; bit.ly/45IMOom;
bit.ly/45nPYy3; bit.ly/3Eb1TDA;
bit.ly/3YLsosP
_______________________
PERSONAL PROFILE
Dr. Liesbeth Ceelen is CEO of BioLizard and has been with the company for more than 4 years. As an experienced leader with a track record in roles ranging from operational, quality, and project management to scientific leadership, sales, and business development, she brings both the scientific background and profound management skills to make BioLizard the go-to bioinformatics consultancy company across Europe and the US.
Sponsored by
![]()





